-
[알고리즘]C++로 구현한 bfsIT&컴퓨터공학/자료구조&알고리즘 2021. 1. 9. 13:15
BFS
너비 우선 탐색
: 시작 정점을 방문한 후에 시작 정점에 인접한 모든 정점들을 우선 방문하는 방법
DFS 와는 달리 ( 스택이용 )
"큐" 를 사용하여 구현한다.
예제

↑위와 같은 그래프가 있다.

준비물
- visited 배열 : 방문한 노드는 true 로 바꿔서, 방문했던 노드를 다시 방문하지 않도록 하기위한 장치
- mem 큐 : dfs 와는 다르게 큐를 사용한다.

1. 시작 노드 "0" 을 큐에 넣는다.
2. "0" 에 대한 visited 를 true 로 바꾼다.

1. "0" 을 큐에서 뺀다.
2. 큐에서 빼져있는 "0" 과 인접한 노드 "1" 과 "2" 를 큐에 차례대로 삽입한다.
3. "1" 과 "2" 의 visited 를 true 로 바꾼다.

1. "0" 을 출력한다.
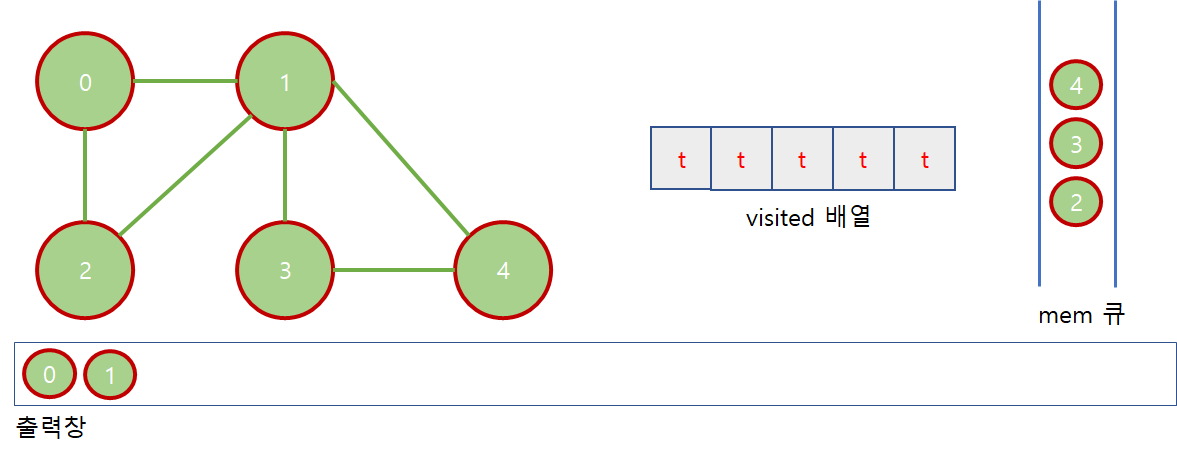
1. "1" 을 큐에서 뺀다.
2. "1" 과 인접한 노드 "2","3","4" 를 큐에 추가하는데, 이때 "2" 는 이미 visited 가 true 이므로 "2"를 제외하고 나머지 두개의 노드만 큐에 추가한다.
3. "3"과 "4"에 대한 visited 도 true 로 바꾼다.
4. "1" 을 출력한다.

1. "2" 를 큐에서 뺀다.
2. "2"와 인접한 "0" 과 "1" 은 이미 방문한 노드이므로 따로 추가되는 노드는 없다.
3. "2" 를 출력한다.

1. "3" 를 큐에서 뺀다.
2. "3"와 인접한 "1" 과 "4" 은 이미 방문한 노드이므로 따로 추가되는 노드는 없다.
3. "3" 를 출력한다.
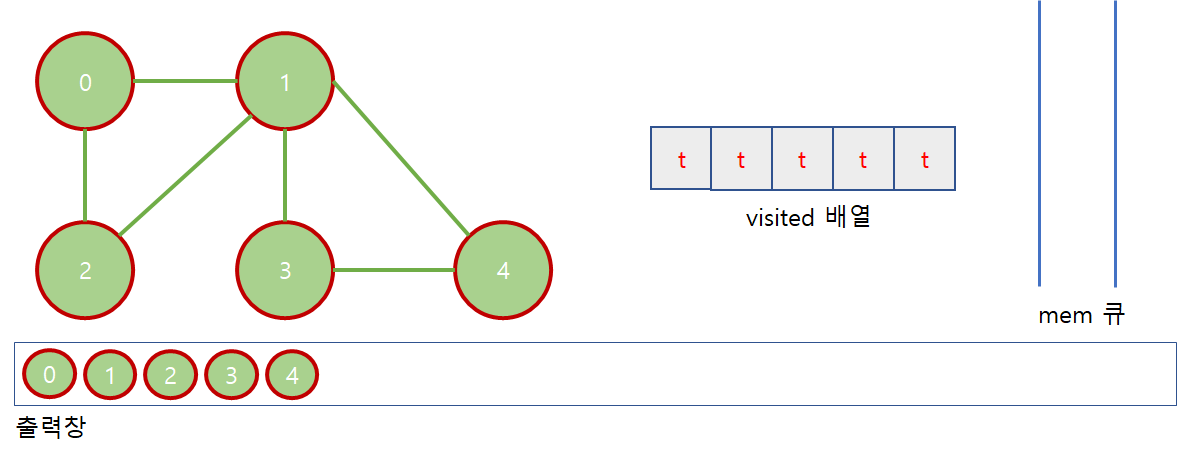
1. "4" 를 큐에서 뺀다.
2. "4"와 인접한 "1" 과 "3" 은 이미 방문한 노드이므로 따로 추가되는 노드는 없다.
3. "4" 를 출력한다.
C++을 이용한 구현
#include<iostream> #include<vector> #include<queue> using namespace std; int V_size=5; // 노드의 갯수 vector< vector<int> > adjacent={ {0,1,1,0,0}, {1,0,1,1,0}, {1,1,0,0,0}, {0,1,0,0,0}, {0,0,0,0,0}, }; //인접 행렬의 표현 vector<bool> visited(V_size, false); // 방문헀으면 true, 안했으면 false queue<int> mem; // 사용할 큐 void bfs(int start) { int current = start; // 제일 처음 루트 노드 mem.push(current); // 큐에 넣고 visited[current] = true; // 방문표시 while (mem.size()!=0) { current = mem.front(); // 큐에서 데이터 하나 꺼내오고 mem.pop(); cout << "VISIT : " << current<< '\n'; for (int i = 0; i < V_size; i++) { if (adjacent[current][i] != 0 && !visited[i]) { // current 와 인접한 노드들 중 방문을 아직 안했고 0 도아니면 mem.push(i); // 큐에 집어넣고 visited[i] = true; // 방문을 true 로 바꾼다 } } } } void bfsAll() { //그래프가 분리되어있을 수 있으니까 모든 그래프를 다 둘러봐야해서 ! visited = vector<bool>(adjacent.size(), false); for (int i = 0; i < adjacent.size(); i++) { if (!visited[i]) bfs(i); // 방문하지 않았으면 dfs 실행 } } void main() { bfsAll(); }장점
- 출발노드에서 목표노드까지의 최단 길이 경로를 보장한다.
단점
- 경로가 매우 길 경우에는 탐색 가지가 급격히 증가함에 따라 보다 많은 기억 공간을 필요로 하게 된다.
- 해가 존재하지 않는다면 유한 그래프(finite graph)의 경우에는 모든 그래프를 탐색한 후에 실패로 끝난다.
- 무한 그래프(infinite graph)의 경우에는 결코 해를 찾지도 못하고, 끝내지도 못한다.
'IT&컴퓨터공학 > 자료구조&알고리즘' 카테고리의 다른 글
[알고리즘] 우선순위 큐 & 힙 (0) 2021.01.10 [알고리즘] Level 2 ) 가장 큰수 - C++ (0) 2021.01.09 [알고리즘] Level2 ) 타겟넘버 C++ 구현 ( DFS 이용 ) (0) 2021.01.07 [알고리즘] C++ 로 구현한 DFS 알고리즘 (2) 2021.01.07 [13] 심화 정렬 ( SORT ) - Heap Sort (0) 2020.07.05 댓글