-
[데이터분석개론] Association Rules & Collaborative FilteringIT&컴퓨터공학/데이터분석개론 2021. 2. 14. 23:07
Association Rules
많은 추천시스템에서 사용하는 Rule이다.
만약 어떤 이가 A라는 상품을 구매하면 후에 B 도 구매한다고 가정하자.
이때 어떤 이가 A라는 상품을 구매하면 을 "선행사건" , B도 구매한다를 "후행결과" 라고 부른다.
예제를 살펴보자 !

해당 예제는 사람들이 어떤 색의 핸드폰 케이스를 샀는지 나타낸다.
우리는 여기서 다양한 Rules 를 발견할 수 있다.
1. 1,4,8,9 번 사람을 보니 red 를 사면 white 도 사는거 같네
2. 혹은 white 를 사면 red 를 사는거 같네
3. white 를 사면 blue 도 사는거 같네
처럼 언뜻보기에 수 많은 rules 를 찾을 수 있다.
사실 모든 아이템의 조합을 찾아내는게 가장 이상적이지만, 현실적으로 핸드폰 케이스가 다양하면 다양해질수록 모든 조합을 찾아내는건 거의 불가능에 가깝다.
따라서 현실적으로는 보통 " 자주 나오는 아이템 집합 " 을 고려한다.
위의 예제를 살펴보자.
자주나오지않는 green , yellow 를 아무리 정확히 예측해봤자 핸드폰 케이스를 많이 파는데는 도움이 되지 못한다.
자주나오는 white, red 같은 아이템과 관련있는 rule 을 찾아야 판매율을 눈에띄게 높일 수 있다.
그리고 어떤색의 케이스가 얼마나 나오는지는 support 를 기준으로 알 수 있다.
support
쉽게 말하면 데이터 셋에서 몇번이나 등장했냐 ? 를 의미한다.
예를들어 { red, white } 집합의 경우 10개의 데이터 중 총 4번 등장했다. 따라서 40%의 support 를 가지고있다.
이제 이 rules 를 찾는 방법 중 대표적인 알고리즘 Apriori Algorithm 에 대해 소개하겠다.
Apriori Algorithm
먼저 탐색을 위한 Transaction 데이터가 필요하다.

Minimum Support 를 설정해줘야하는데, 임의로 4로 설정하겠다.

이제 위처럼 아이템별로 support 를 계산한다.
우리는 minimum support 기준을 5로 잡았기 때문에 4보다 낮은 1번 아이템은 제외된다.
이제 이를 바탕으로 Self-Join 과 Prune 과정을 거친다.
Self-Join 은 남은 아이템 {2},{3},{4} 를 가지고 만들 수 있는 길이가 2인 모든 후보를 만드는 과정이다.
따라서 {2,3},{3,4},{2,4} 가 생성될 것이다.
이렇게 만들어진 후보로 이제 Prune 과정을 진행한다.
{2,3} 의 subset {2} 와 {3} 의 경우엔 위 표에서 제외되지않았으므로 프루닝대상이 아니다.
{3,4},{2,4} 역시 마찬가지다.
이제 다시 Self-Join 을 통해 {2,3},{3,4},{2,4} 를 가지고 길이가 3인 후보를 만들자.
{2,3,4} 가 나온다.
이제 Prune 과정을 진행한다.
{2,3,4} 의 subset {2,3},{3,4},{2,4} 의 경우 위 표에서 제외되지않았으므로 프루닝 대상이 아니다.
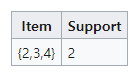
minimum support 4보다 더 큰 아이템 셋이 없으므로 이제 종료한다.
위의 과정을 통해 우리는 어떤 아이템들이 빈번하게 묶이는지 알 수 있다.
그렇다면 우리가 묶은 이 아이템들이 실제로 얼마나 연관이 있는지 측정해보자 !
Confidence

confidence 는 support 와 주는의미가 조금다른데,
confidence 는 선행사건 + 후행결과 / 선행사건 을 의미한다.
예를들어 100,000 개의 거래 데이터가 있다고 가정하자.
이 데이터 중 오렌지 주스와 감기약을 같이 산 경우가 2000, 그 2000 중 800 건은 수프를 같이샀다.
support 의 경우 해당 rule 이 몇번이나 나왔냐 ? 를 뜻하므로,
이 경우 오렌지 주스와 감기약을 산 경우, 수프도 같이 산 association rule 은 800/100,000 = 0.08% 이라는 support 값을 가진다.
confidence 의 경우, 800/2000 = 40 % 라는 값을 가진다.
Lift Ratio


내가 이 rule 을 가지고 아이템 A를 사라고 조언을 해줬을 때 , 이사람이 진짜로 사게되면 나한테 얼마나 이득이 되냐 ? 를 나타내는 값이다.
만약 이 값이 1이라면 이 사람은 내가 조언을 해주지않았더라도 원래 이 물건을 같이 살 생각이였으므로 매출이 더 올라갔다고 볼 순 없다.
이 값이 1 이상으로 올라가야 내가 권유해서 샀으므로 실제로 매출에 기여했다고 말할 수 있다.
Rule Selection
- 충분한 support 를 가지는 item sets 를 선택하자
- 이 item sets 중에서 충분한 confidence 를 가지는 세트를 선택하자. ( 보통 0.5 이상 )
- 이렇게 고른 세트 중에서 lift 가 큰 세트가 가장 좋다. ( 1 이상 )
Apriori Algorithm 의 단점
- 주관성이 들어간다.
- 얼마나 support 가 높으면 남길지 ,
- 얼마나 Lift 가 높으면 남길지 등등 우리가 결정하기 때문에 주관성이 들어간다.
'IT&컴퓨터공학 > 데이터분석개론' 카테고리의 다른 글
[데이터분석개론]Cluster Analysis (1) 2021.02.16 [데이터분석개론] Collaborative Filtering (0) 2021.02.15 [데이터분석개론] Naïve Bayes Classifier. 나이브베이즈 분류 (0) 2021.02.13 [데이터분석개론] K-Nearest Neighbors (0) 2021.02.13 [데이터분석개론]Logistic Regression . 로지스틱 회귀분석 (0) 2021.02.13 댓글